
Embrace Serverless ETL with AWS Glue : Oracle DB to AWS Redshift
Serverless computing is most suitable for applications in which a business, or a person who owns the system, does not have to purchase, rent or provision servers or virtual machines for the back-end code to run on. It is highly cost-effective, as you do not have to invest in dedicated hardware, infrastructure and support.
Go Serverless with AWS Glue
AWS Glue is a perfect Extract, Transform, and Load (ETL) tool that justifies the term
“serverless”. Working with Glue does not involve any virtual machines/server. Unlike other
ETL tools like Talend, AWS Glue does not also require licensing and an infrastructure to
setup. In short, it enables you to be completely “Serverless”.
How does AWS Glue Work?
AWS Glue is a fully managed ETL service that makes it easy for you to prepare and load the
data for analytics. You can create and run an ETL job with a few clicks in the AWS
Management Console. You can simply point AWS Glue to your data stored on AWS, and
AWS Glue discovers your data and stores the associated metadata (e.g. table definition and
schema) in the AWS Glue Data Catalog. Once cataloged, your data is immediately
searchable, queryable and available for ETL. AWS Glue can be best explained with a use case
of leveraging Serverless Computing for ERP analytics on Redshift.
ERP Analytics on Redshift with Data from On-premises Store
We can transform and move data from an on-premises data store (Oracle) to Redshift using
AWS Glue. AWS Glue simulates a common data lake ingestion pipeline to connect to a
variety of on-premises JDBC data stores, such as PostgreSQL, MySQL, Oracle, Microsoft SQL
Server and MariaDB. AWS Glue ETL jobs can use them as sources to extract data, transform
it, and load the resulting data back to target data store (Redshift) in AWS.
AWS Glue establishes a network connection using VPN (Virtual Private Network) or Direct
Connect (DC) to connect the source to the target database. An AWS Glue crawler uses an S3
or JDBC connection to catalog the data source, and the AWS Glue ETL job uses S3 or JDBC
connections as a source or target data store.
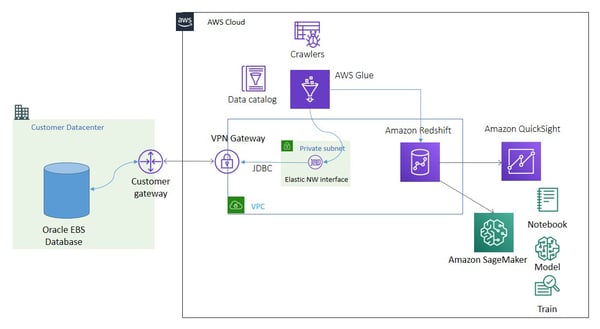 Establishing a JDBC Connection
Establishing a JDBC Connection
- Create a Self referencing Security Group for AWS Glue ENI in your VPC.
- Create an IAM Role for AWS Glue.
- Add a JDBC connection.
- Open appropriate firewall ports in the on-premises data center.
- Test the JDBC connection.
The JDBC connection defines parameters for a data store. For example, when AWS Glue
establishes a JDBC connection to the OracleDB server running on an on-premises network, it
creates Elastic Network Interfaces (ENIs) in a VPC/private subnet. These network interfaces
then provide network connectivity for AWS Glue through your VPC. Security groups
attached to ENIs are configured by the selected JDBC connection.
Optionally, a NAT gateway or NAT instance setup in a public subnet provides access to
internet, if an AWS Glue ETL job requires either access to AWS services using a public API or
outgoing internet access.
Performing ETL to Crawl Data Using JDBC Connection
- Set up a crawler that points to the Oracle database table and creates a table
metadata in the AWS Glue Data Catalog as a data source. - Run the ETL job to move the data for the table.
Performing ETL to Move Data Directly to the Target (Redshift)
- Create a custom script that contains the connection parameters of source and
target, and the code for migrating the table. - Upload the custom script and the dependent jar/library files (required for connecting
datastores) to S3 bucket. - Configure ETL job and mention the S3 paths of script and relevant dependencies in
job run.
Serverless Computing for your Business
Data Analytics is one of those applications suitable for Serverless Computing. We at
OneGlobe leverage this technology for other applications as well. Contact us to know more
about how you can adopt Serverless Computing to create innovative and cost-effective
solutions to increase productivity and achieve cost savings.
To know how OneGlobe can help you seamlessly migrate to the cloud visit https://bit.ly/2LF19gA






